The Ávila Bible Case
Explore the Avila Bible, a 12th-century manuscript, using data science to predict its scribes.
The Avila Bible case consists of a dataset that has been created from 800 images of the Abila Bible. The Avila Bible is a giant Latin copy of the whole Bible from the 12th century (Stefano, Fontanella, Maniaci, Freca, 2018). Manuscript studies showcase different methods and techniques of analysis that is applicable in different areas of the industry (Herman, Ransom, 2023). Here, this is utilised for the purpose of exploring the world of computing technology through a core step in data science. The Avila Bible Case is the study of standardised handwriting and book typology that dives into the analysis of basic layout features, page organisation, and exploitation of available space which provides signicant ndings that can be used to develop a predictive system that will identify the scribes who worked together to write the Avila Bible.

An example of a page of the Avila Bible
src: https://medievalbooks.nl/category/medieval-scribes/page/2/
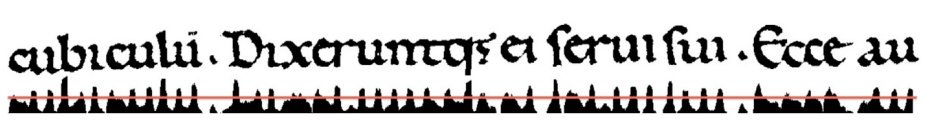
Findings of the pixel projection histogram for the number of peaks on the horizonal axis of a written row.
src: https://www.sciencedirect.com/science/article/abs/pii/S0952197618300721
In this project, I went through the data science process with the use of the Avila Bible Case dataset to focus on a core step, data modelling. This is intended for gaining practical knowledge by following the steps of data modelling, presentation and automation.
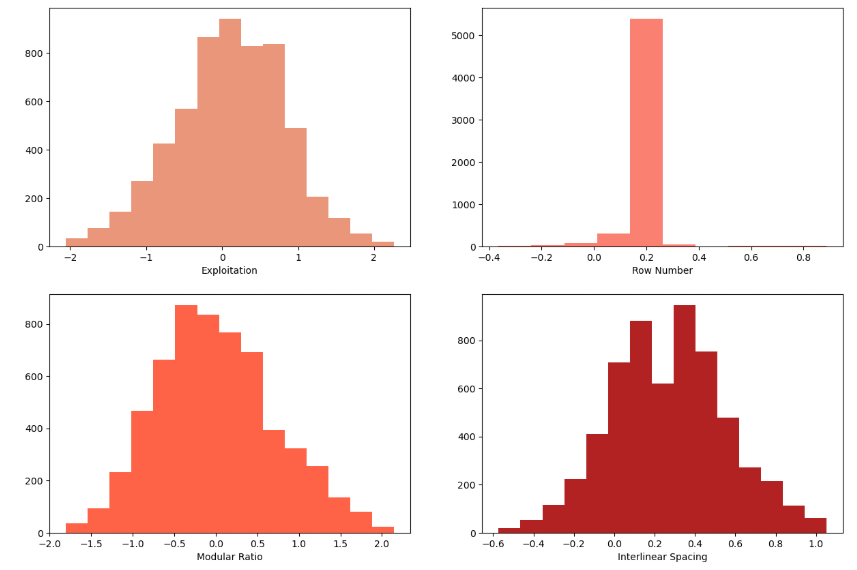
Exploitation of written area per column
I used two different methods for modelling, namely the K-Nearest Neighbour method and the Decision Tree method. The evaluation of these models was done through K-Fold Cross Validation to confirm and compare the effectiveness of the two models in predicting and identifying the scribes, given a set of trained typological features/data against the test set.
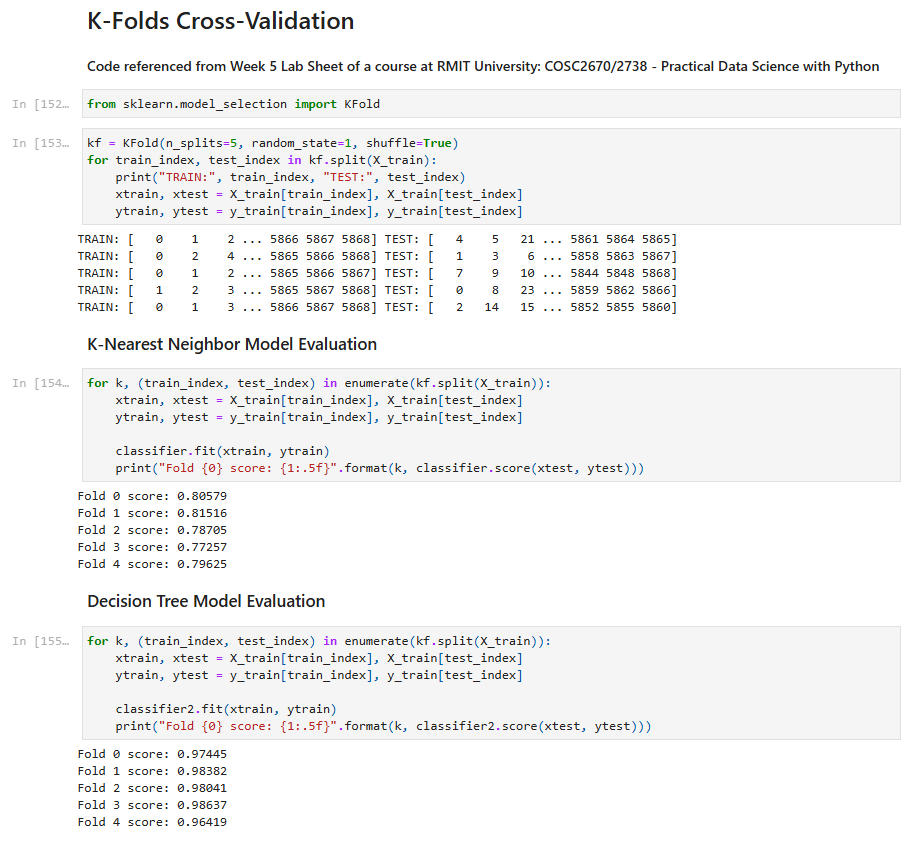
Validation of the models
Conclusion
The Decision Tree model demonstrated superior performance in scribe recognition. It achieved an accuracy of 0.99, which is signicantly higher than the KNN model’s 0.82. Data exploration revealed that the exploitation of each column in the written area was the most signicant contributing factor in distinguishing scribes. Whereas features correlated to column exploitation further enhanced the model’s ability to accurately identify scribes. This high accuracy and reliability suggests that the Decision Tree model is highly effective for distinguishing scribes based on typological features from the Avila Bible, providing a robust tool for historical manuscript analysis. Future work should explore ensemble methods and larger datasets to further enhance model performance and applicability.
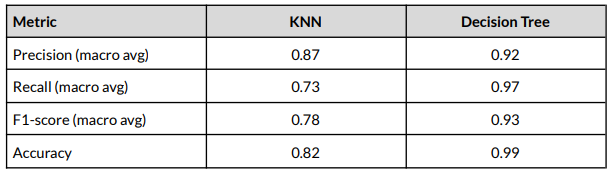
Findings
For the full report, please visit the repository for this project:
https://github.com/labelenn/Avila-Bible-Case